The idea behind the APnA City Program is to create a baseline for air pollution for cities across India. With a starting point and an estimate of source contributions to pollution, policy makers can chart out strategies to improve air quality. One of the main issues is that data in an easy to use format has been hard to come by and most of the estimates and information that we have compiled for this project are the only available information (especially in the case of tier-2 cities).
A brief description of the methods we have used to estimate the emissions and concentrations by source for each of these cities is as follows;
- Compile an emissions inventory covering major sources for each city
- Spatially grid the emission inventory at a 0.01° grid resolution in longitude and latitude (equivalent of 1 km) to create a spatial map of emissions for each pollutant (PM2.5, PM10, SO2, NOx, CO and VOCs)
- Use a meteorological model to construct meteorological fields
- Use a dispersion model to estimate concentration of pollutants by source
- Create scenarios for the medium/long term using SIM-air (Simple Interactive Models for better air quality) framework

 |
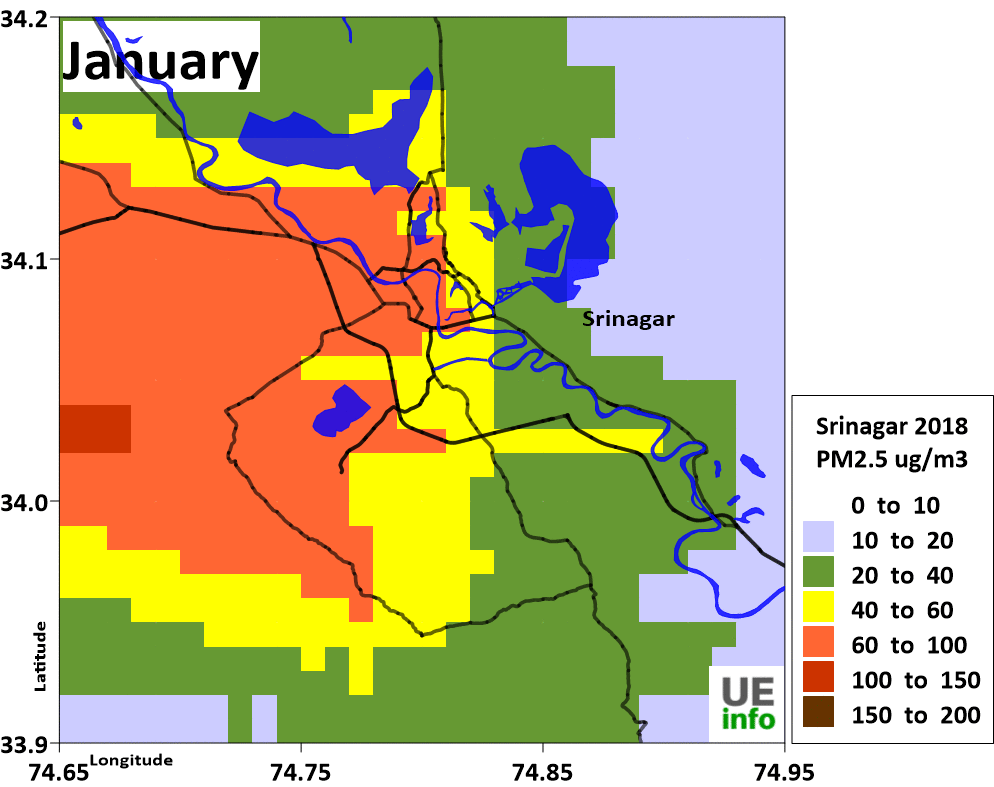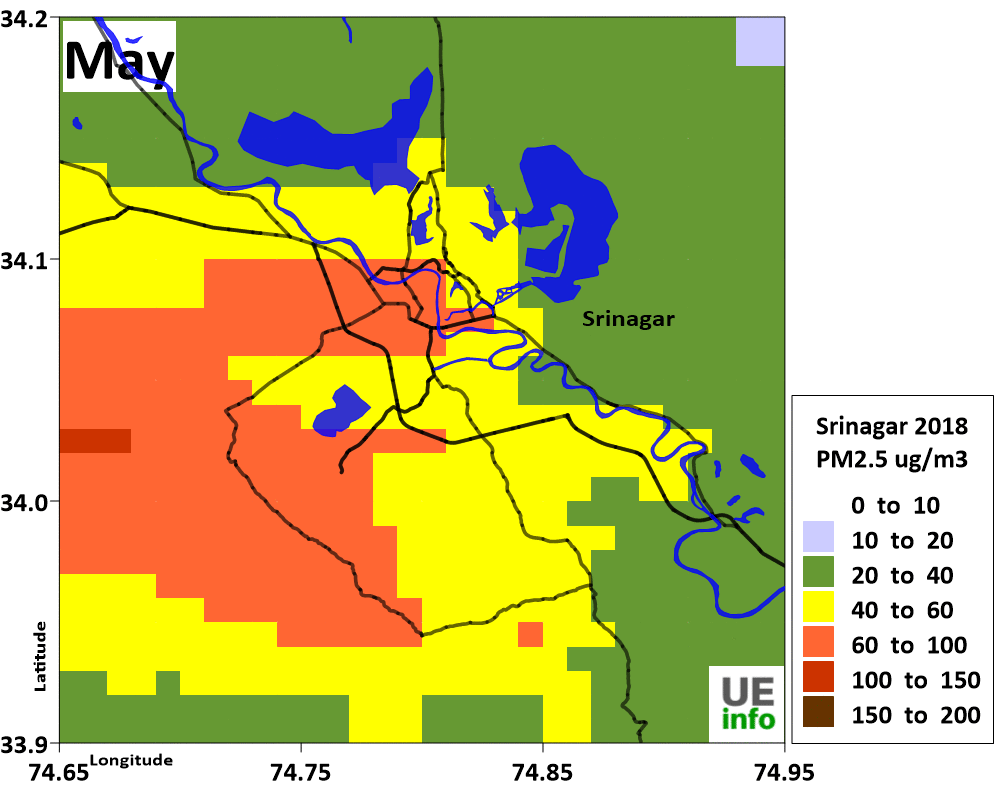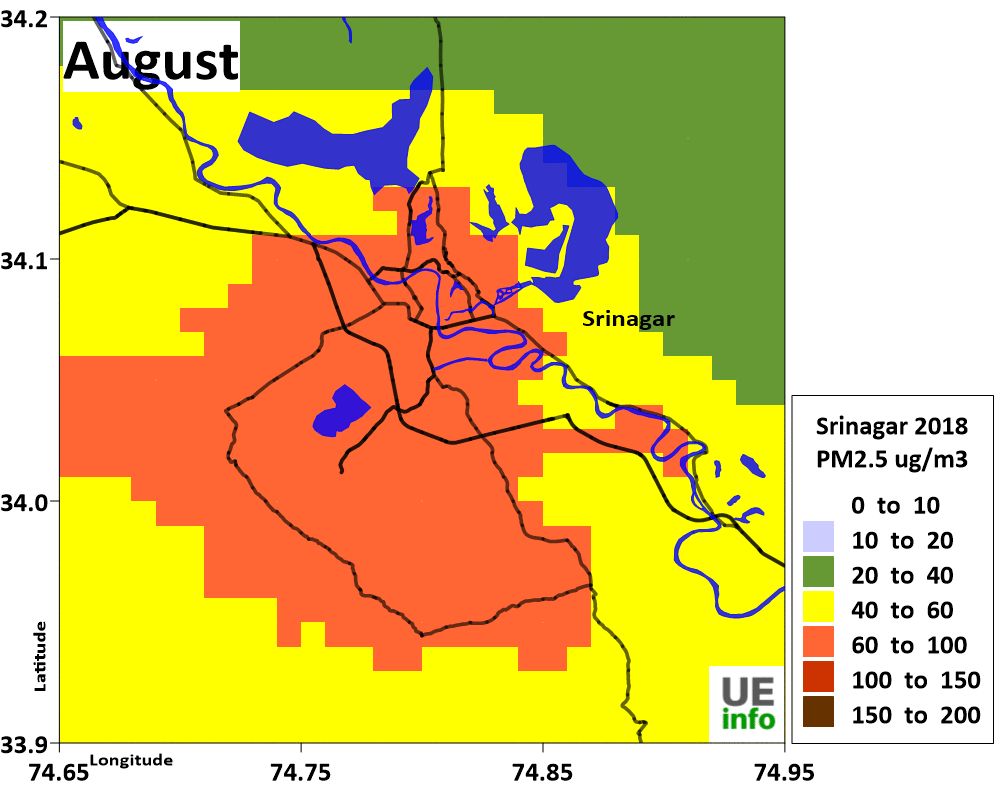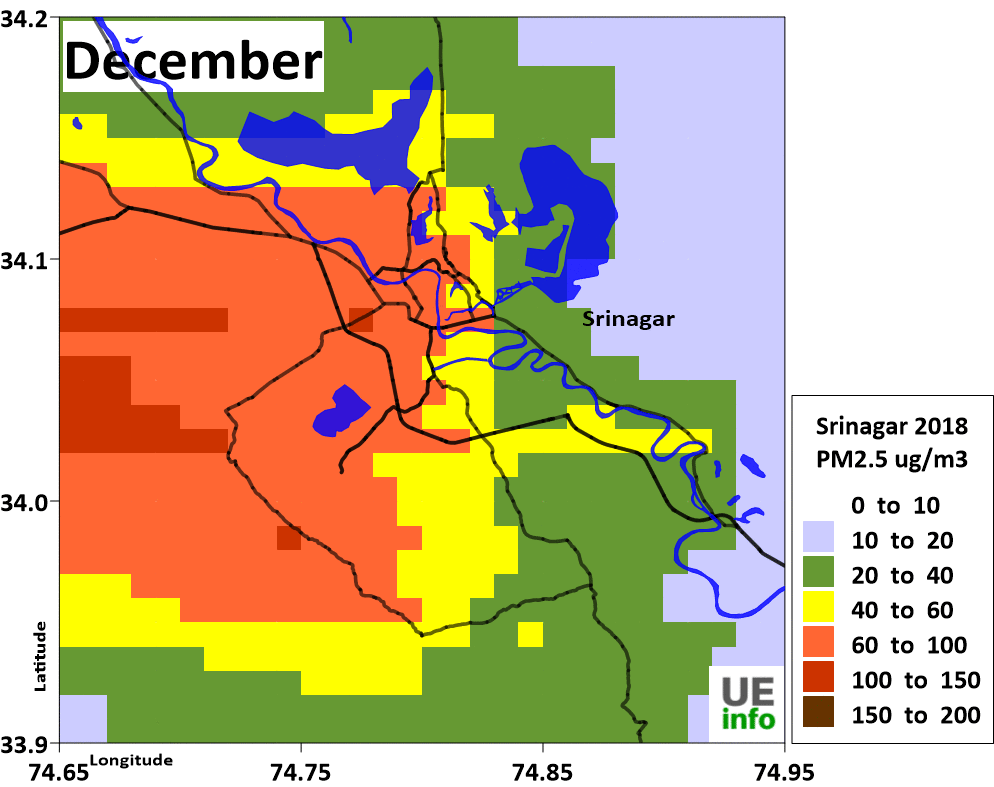 |
 |
Emissions
We developed an emissions inventory for each of the cities for the following pollutants – sulfur dioxide (SO2), nitrogen oxides (NOx), carbon monoxide (CO), non-methane volatile organic compounds (NMVOCs), and carbon dioxide (CO2); and particulate matter (PM) in four bins (a) coarse PM with size fraction between 2.5 and 10 μm (b) fine PM with size fraction less than 2.5 μm (c) black carbon (BC) and (d) organic carbon (OC), for year 2015 and projected these numbers to year 2030 under pre defined scenarios.
We then customized the SIM-air family of tools to fit the base information collated from several sources including; the central pollution control board, state pollution control board, census bureau, ministry of road transport and highways, annual survey of industries, municipal waste management, and meteorology. Note that there are many factors that influence the changes in a city’s social, economic, landuse, urban, and industrial layout and hence the growth rates assumed should be considered as an estimate only. Given the air quality status in the city, reflected in the monitoring feeds, we used these estimates to evaluate the likely trend in city’s total emissions, their likely impact on the ambient particulate matter (PM) concentrations, and health impacts through 2030.
The emission inventory for each city is based on the local activity and fuel consumption estimates for the selected urban airshed and does not include natural emission sources (like dust storms, lightning, and sea salt) and seasonal open (agricultural and forest) fires; which can only be included in a regional scale simulation. That said, we do account for these emission sources in the pollution concentration calculations as an external (boundary or long-range) contribution to the city’s air quality.
The emissions inventory for the baseline projections include the following sectors;
TRAN = transport sector emissions, includes on-road (passenger and freight) and aviation activities
RESI = residential sector, includes cooking, heating, and lighting activities
INDU = industrial sector, includes light and heavy duty sectors
DUST = resuspended dust from on-road activities and construction activities
WAST = open waste burning
DGST = diesel generator sets to supplement any load shedding in the region
BRIC = brick kiln sector, which is carved out of the industrial emissions, because of its significant contribution to the city’s air quality.
In case of the transport sector, we used grid based population density, road density (defined as number of km per grid), and commercial activity like industries, brick kilns, hotels, hospitals, apartment complexes, cinemas, telecom tower density, and markets, to distribute emissions on feeder, arterial, and main roads.
We allocated emissions from industry to industrial estates and brick kiln emissions to the clusters. Population density determined the distribution of emissions for the domestic sector and garbage burning emissions.
Gridding the Emission Inventory:
We then spatially segregate the emissions inventory at a 0.01° grid resolution in longitudes and latitudes (equivalent of 1 km), to calculate pollution concentration levels using atmospheric dispersion modeling.
The schematics of the emission gridding procedure are presented below.

Levels on Uncertainty in Emissions Distribution:
Since, the inventory is based on bottom-up activity data in the city and secondary information on emission factors in India (and elsewhere), the overall estimation has an uncertainty of ±20-30%. In the transport sector, the largest margin is in vehicle km traveled and vehicle age distribution with an uncertainty of ±20% for passenger, public, and freight transport vehicles. The silt loading, responsible for road dust resuspension, has an uncertainty of ±25%, owing to continuing domestic construction and road maintenance works, which also vary with the road type. In the brick manufacturing sector, the production rates which we assumed constant per kiln, has an uncertainty of ±20%. The data on fuel for cooking and heating in the domestic sector is based on national census surveys with an uncertainty of ±25%. Though lower in total emissions, open waste burning along the roads and at the landfills has the largest uncertainty of ±50%. The fuel consumption data for the in-situ generator sets is based load shedding rates, has an uncertainty of ±30%.
Meteorology
To forecast the meteorological conditions (3D wind, temperature, pressure, relative humidity, and precipitation fields) we used the National Center for Environmental Prediction (NCEP) global reanalysis database for the base year 2010-11 and WRF 3.5 meteorological model at 1 h temporal resolution. The initial conditions for the dispersion model were extracted from the MOZART global chemical transport model, for which an interface is available with the CAMx model.
Dispersion
Using the gridded emissions inventory and short term meteorological forecasts, we model the atmospheric dispersion of pollutants (WHICH) to study the impact of the emissions on ambient PM concentrations.
We use the ENVIRON – Comprehensive Air Quality Model with Extensions (CAMx), an Eulerian photochemical dispersion model, suitable for integrated assessments of gaseous and particulate air pollution over many scales ranging from sub-urban to continental.
The model formulation, advection and scavenging schematics, chemical solvers, and gas-to-aerosol conversion mechanisms, are detailed in the model manual (http://www.camx.com). The model utilizes full gas phase SAPRC chemical mechanism (Carter et al., 2000) (217 reactions and 114 species) with two mode coarse/fine PM fractions including gas to aerosol conversions, for SO2 to sulfates, NOx to nitrates, and VOCs to secondary organic aerosols (SOA). The most important advantage of CAMx is the use of 3D meteorology and independently controled plume rise and emission release point for each emission source.
While there are other atmospheric dispersion models, equally capable of carrying out this modeling exercise. We selected the CAMx model because of its modular nature in characterizing and treating the plumes from point sources.
Back to the APnA page.
All the analysis and results are sole responsibility of the authors @ UrbanEmissions.Info. Please send you comments and questions to simair@urbanemissions.info